|
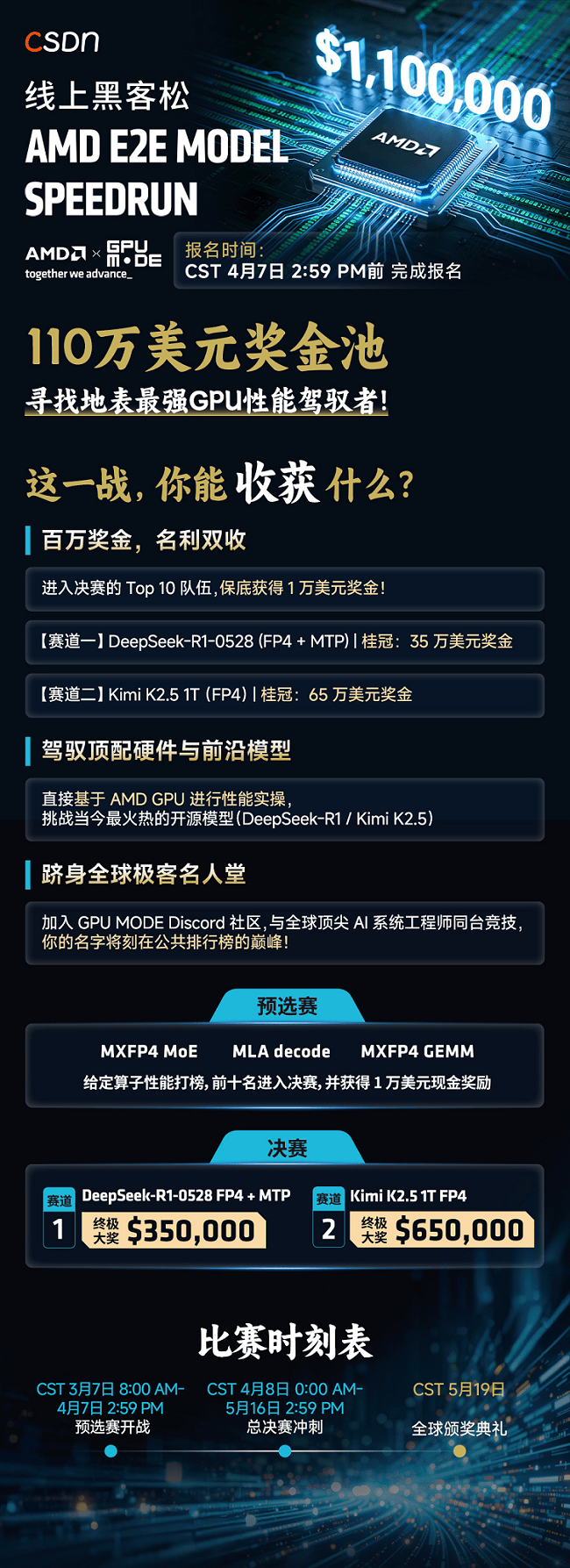
在DeepSeek-R1和Kimi K2.5等顶级开源模型确立了万亿参数的工业基准后,真正的极限性能压榨才刚刚开始。谁能在极高并发下打破内存墙?谁能用最优雅的代码实现最高效的算子重构?在当下的AI战场,速度即是正义,吞吐量决定生死。由AMD与GPU MODE联合发起的极客巅峰对决,正式向全球发榜:2026线上黑客松:AMD E2E Model Speedrun正式吹响集结号! ·在这里,你将直接操控AMD专为大模型打造的顶配云端GPU阵列 ·在这里,没有纸上谈兵的PPT,只有硬核的绝对速度与吞吐量。 ·在这里,你的极限优化不仅能赢取巨额美金,更将直接合入主流开源框架,定义下一代AI推理的工业标准! 作为本次活动的战略社区合作伙伴,CSDN将全程见证这场智力与算力的巅峰对决。 你,敢来迎战吗?
立即报名:AMD×GPU MODE - E2E Model Speedrun • Luma (https://luma.com/cqq4mojz?utm_campaign=adp-aig&utm_medium=social&utm_source=csdn&utm_term=hackathon) 百万美金奖池,凭实力“拿钱” 本次挑战赛设立了高达110万美元的总奖金池!只要你的技术够硬,名与利双丰收。 决赛入围奖:只要从预选赛杀出重围,跻身Top 10,每支队伍保底斩获10,000美金! Track 1赛道桂冠(DeepSeek-R1-0528):$350,000独揽! Track 2赛道桂冠(Kimi K2.5 1T FP4):$650,000独揽! 注:两大赛道完全独立,有实力的团队完全可以双线作战,包揽百万美金! 赛制硬核,分秒必争的“大逃杀” ·比赛绝非易事,本次大赛将采用“底层算子突围+端到端决赛大考”的双阶段赛制。能留到最后的,注定是地表最强的性能架构师。 ·预选赛——底层内核的绝对厮杀 所有参赛者需对三大核心GPU算子进行极限打磨: 1、MXFP4 MoE(最高1500分) 2、MLA Decode(最高1250分) 3、MXFP4 GEMM(最高1000分)每个内核问题的得分=最大分值×[1-(排名分值/20)]。排名按顺序所对应分值=0,1,2,…18,19。总分为三项内核问题得分之和,采用上述方法。只有排名前20的算子才能获得积分,总分排名前10的战队/个人,方可拿到通往决赛的门票。 总决赛——真实世界的端到端狂飙 Top 10 选手将获得 AMD 提供的单节点8卡云端Instinct™ GPU集群。你们需要在极致并发下,挑战两大明星模型: ·赛道 1:DeepSeek-R1-0528 FP4 + MTP ·赛道1评判标准
在4、32、128三种并发度下,你不仅要保证极高的吞吐量(Token Throughput),还要死守低延迟的交互性(Interactivity),更要确保模型精度不能掉(本赛道要求GSM8K≥0.93)。性能门槛(三个并发级别必须同时达标): ·赛道2:Kimi K2.5 1T FP4 ·赛道2评判标准 在4、32、128三种并发度下,你不仅要保证极高的吞吐量(Token Throughput),还要死守低延迟的交互性(Interactivity),更要确保模型精度不能掉(如Track 1要求GSM8K≥0.93)性能门槛(三个并发级别必须同时达标):
评分:Token Throughput per GPU(最高600分)+Interactivity(最高400分),三个并发级别满分3000分。 跑分不是终点 我们寻找的不是为了跑分的“特供版代码”,而是能真正造福全人类AI社区的工业级优化。终极必杀规则:代码必须可Merge!所有具备获奖资格的团队,其提交的代码必须在赛后2-4周内,在AMD工程师的指导下,成功向AMD官方仓库(AMD ATOM / vLLM / SGLang)发起Pull Request并完成合并。让你的名字,永远镌刻在推动大模型时代前行的开源主分支上! 决战时刻表(北京标准时间) ·报名&预选赛截止时间:4月7日2:59 PM(TOP 10诞生) ·决赛排位战:4月8日0:00 AM——5月16日2:59 PM ·全球颁奖典礼:5月19日 如何加入这场算力狂欢? 无论你是AI底层优化老兵、CUDA/Triton极客,还是系统架构师、开源社区贡献者,只要你对AI系统性能工程充满狂热,这里就是你的主场!(支持个人或至多3人组队参赛) 第一步:加入AMD AI Developer Program,获取官方弹药库。 AI开发者计划注册表:https://www.amd.com/zh-cn/registration/ai-dev-program-sign-up-form.html 第二步:查阅预选赛参考kernels,使用Popcorn CLI准备你的提交。预选赛入口及工具库:https://github.com/gpu-mode/reference-kernels,别一个人战斗!立刻加入GPU MODE Discord社区及微信比赛专属群,与全球顶尖开发者同频共振,获取实时赛事更新与官方技术支持! |
免责声明:本网站内容由网友自行在页面发布,上传者应自行负责所上传内容涉及的法律责任,本网站对内容真实性、版权等概不负责,亦不承担任何法律责任。其原创性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容、文字的真实性、完整性、及时性本站不作任何保证或承诺,并请自行核实相关内容。本站不承担此类作品侵权行为的直接责任及连带责任。如若本网有任何内容侵犯您的权益,请及时联系我们,本站将会在24小时内处理完毕。